过去三年我一直在面试工程师,并问他们问同一个问题:“请告诉我一次你遇到数据库性能问题的经历。”
答案出奇地一致:
“我们加了索引”
“我们换了个数据库”
“我们加了缓存”
“我们实现了读副本”
这些都是有效的解决方案,但它们都是治标不治本。
真正的问题是什么?大多数团队把数据库当作愚蠢的存储桶,而不是强大的处理引擎。
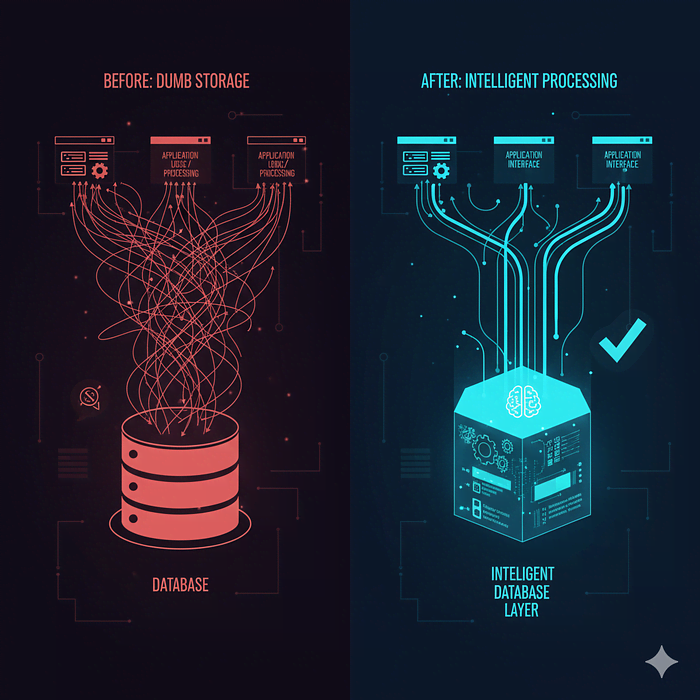
我是付出了惨痛代价才明白这一点的!接下来,让我告诉你我们是如何让应用程序濒临崩溃,以及我们如何通过减少代码中的工作、增加数据库中的工作来修复它。
我们构建了很普遍的一个分析仪表板:显示不同时间段、区域和产品类别的收入指标(基本的企业智能内容)。
我们最初的实现很简单,获取所有数据,在Node.js中处理,发送到前端:
async function getRevenueDashboard(filters) { const orders = await db.query(` SELECT id, amount, created_at, product_id, region, customer_id FROM orders WHERE created_at > NOW() - INTERVAL '1 year' `); const products = await db.query(` SELECT id, name, category FROM products `); const productMap = products.reduce((acc, p) => { acc[p.id] = p; return acc; }, {}); const result = { totalRevenue: 0, byCategory: {}, byRegion: {}, byMonth: {} }; orders.forEach(order => { const product = productMap[order.product_id]; const category = product?.category || 'Unknown'; const month = order.created_at.toISOString().substring(0, 7); result.totalRevenue += order.amount; result.byCategory[category] = (result.byCategory[category] || 0) + order.amount; result.byRegion[order.region] = (result.byRegion[order.region] || 0) + order.amount; result.byMonth[month] = (result.byMonth[month] || 0) + order.amount; }); return result;}
第一个月:5000个订单。响应时间:200毫秒。大家都很开心。
第三个月:50000个订单。响应时间:800毫秒。开始感觉慢,但可以接受。
第六个月:180000个订单。响应时间:3.2秒。业务团队开始抱怨。
第九个月:350000个订单。响应时间:7.8秒。CEO发了条Slack消息:“为什么仪表板这么慢?”
我们尝试了通常的修复方法:
在 created_at 和 product_id 上添加了索引(有点帮助)
实现了Redis缓存(有帮助,但缓存巨大且失效是个噩梦)
优化了JavaScript处理(也许节省了200毫秒)
没什么真正管用!根本问题仍然存在:我们正在通过网络拉取数十万行数据,将它们保存在内存中,并做那些数据库本可以快1000倍完成的数学运算。
我们的数据库顾问(是的,我们雇了一个)看了我们的代码大约30秒,然后说:“你们为什么要在Node里做所有这些事?”
“因为……业务逻辑就在那里?”
他重写了我们的查询:
WITH monthly_revenue AS ( SELECT DATE_TRUNC('month', o.created_at) as month, p.category, o.region, SUM(o.amount) as revenue FROM orders o JOIN products p ON o.product_id = p.id WHERE o.created_at > NOW() - INTERVAL '1 year' GROUP BY DATE_TRUNC('month', o.created_at), p.category, o.region)SELECT (SELECT SUM(revenue) FROM monthly_revenue) as total_revenue, ( SELECT json_object_agg(category, category_revenue) FROM ( SELECT category, SUM(revenue) as category_revenue FROM monthly_revenue GROUP BY category ) cat ) as by_category, ( SELECT json_object_agg(region, region_revenue) FROM ( SELECT region, SUM(revenue) as region_revenue FROM monthly_revenue GROUP BY region ) reg ) as by_region, ( SELECT json_object_agg(month, month_revenue) FROM ( SELECT month, SUM(revenue) as month_revenue FROM monthly_revenue GROUP BY month ORDER BY month ) mon ) as by_month;
拥有350000个订单时的响应时间:47毫秒。
不是打字错误!从7.8秒到47毫秒,提升了166倍。
我们新的Node.js代码:
async function getRevenueDashboard(filters) { const result = await db.query(` -- That whole SQL query above `); return result.rows[0];}
就这样,数据库完成所有工作,Node只返回结果。
大多数开发者(包括过去的我)都犯了同样的错误。我们这样看待数据库:
所以我们这样写代码:
但现代数据库并非愚蠢的存储,PostgreSQL、MySQL、SQL Server——这些都是复杂的计算引擎,它们可以:
高效地连接表
聚合数据
用复杂条件过滤
进行数学运算
转换数据
执行业务逻辑
返回JSON、XML或你需要的任何格式
当你从数据库中取出数据并在应用程序中处理时,你正在:
通过网络传输大量数据
解析和反序列化这些数据
将其加载到内存中
用更慢、优化程度更低的代码处理它
序列化结果
通过网络发送回去
数据库可以跳过步骤1-6,直接给你答案。
const users = await db.query('SELECT * FROM users');for (const user of users) { const orders = await db.query( 'SELECT * FROM orders WHERE user_id = ?', [user.id] ); user.orderCount = orders.length; user.totalSpent = orders.reduce((sum, o) => sum + o.amount, 0);}
如果有1000个用户,这就执行了1001次数据库查询。
// Good: One queryconst users = await db.query(` SELECT u.*, COUNT(o.id) as order_count, COALESCE(SUM(o.amount), 0) as total_spent FROM users u LEFT JOIN orders o ON u.id = o.user_id GROUP BY u.id`);
一次查询,数据库完成所有工作。
const products = await db.query('SELECT * FROM products');const available = products.filter(p => p.stock > 0 && p.price < 100 && p.category === 'electronics' && !p.discontinued);
你刚刚通过网络拉取了50000个产品,只为了找到12个。
SELECT * FROM productsWHERE stock > 0 AND price < 100 AND category = 'electronics' AND discontinued = false;
数据库有索引,它知道如何高效过滤,利用它。
const orders = await db.query(` SELECT amount, tax_rate FROM orders`);orders.forEach(order => { order.taxAmount = order.amount * order.tax_rate; order.total = order.amount + order.taxAmount;});-- Good: Compute in databaseSELECT amount, tax_rate, amount * tax_rate as tax_amount, amount + (amount * tax_rate) as totalFROM orders;
SQL为此做了优化,JavaScript没有。
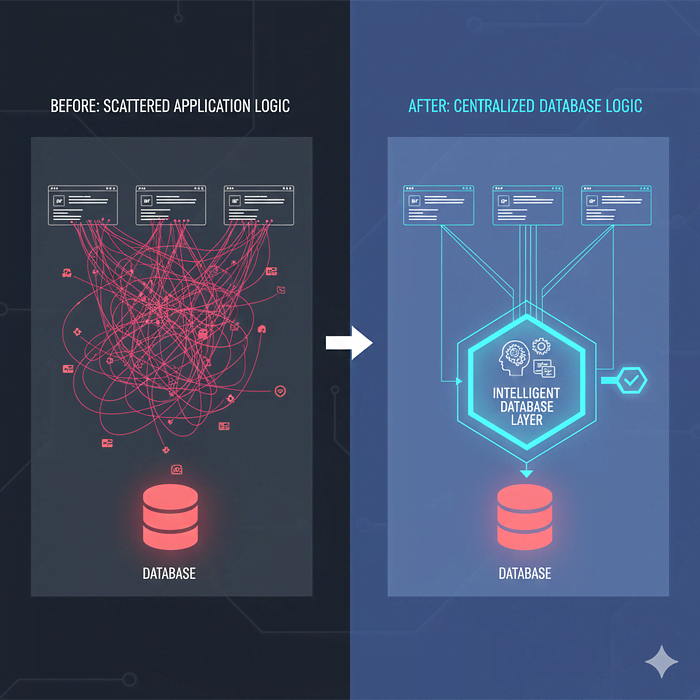
也许现在是够快。但是考虑一下:
当你的数据增长10倍时会发生什么?
当你有并发用户时呢?
当你的API在高峰时段被猛烈访问时呢?
这就是数据库端处理能带来巨大差异的地方:
任何类型的聚合、分组或统计分析都应该在数据库中进行。毫无疑问。
SELECT product_id, COUNT(*) as order_count, SUM(quantity) as total_quantity, AVG(price) as avg_price, PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY price) as median_priceFROM order_itemsWHERE created_at > NOW() - INTERVAL '30 days'GROUP BY product_idHAVING COUNT(*) > 10ORDER BY total_quantity DESCLIMIT 100;
尝试在应用程序代码中做这个?你会把数百万行加载到内存里。数据库在毫秒内完成。
const allUsers = await db.query('SELECT * FROM users');const sorted = allUsers.sort((a, b) => b.created_at - a.created_at);const page = sorted.slice(offset, offset + limit);
你获取了100000个用户只为了显示20个。
SELECT * FROM usersORDER BY created_at DESCLIMIT 20 OFFSET 0;
人们认为业务逻辑必须存在于应用程序代码中,但数据库可以处理它:
WITH customer_orders AS ( SELECT customer_id, SUM(total_amount) as total_spent, COUNT(*) as order_count, MAX(created_at) as last_order_date FROM orders WHERE status = 'completed' GROUP BY customer_id),customer_segments AS ( SELECT c.id, c.email, co.total_spent, co.order_count, co.last_order_date, CASE WHEN co.total_spent > 10000 THEN 'vip' WHEN co.total_spent > 5000 THEN 'premium' WHEN co.total_spent > 1000 THEN 'regular' ELSE 'new' END as segment, CASE WHEN co.last_order_date > NOW() - INTERVAL '30 days' THEN 'active' WHEN co.last_order_date > NOW() - INTERVAL '90 days' THEN 'at_risk' ELSE 'churned' END as status FROM customers c LEFT JOIN customer_orders co ON c.id = co.customer_id)SELECT * FROM customer_segmentsWHERE segment = 'vip' AND status = 'at_risk';
这种逻辑写成SQL,通常比写成带有多个循环和条件判断的应用程序代码,更具可读性和可维护性。
ORM对于CRUD操作来说很棒。但对于复杂查询来说它们很糟糕,因为它们强迫你从对象的角度思考,而不是集合的角度。
const users = await User.findAll({ include: [{ model: Order, required: false }]});
ORM获取了比需要多得多的数据,而你仍然需要处理它。
我的原则是用ORM进行简单的读写操作。对于任何涉及以下内容的操作,降级到原始SQL:
const user = await User.findByPk(userId);user.email = newEmail;await user.save();const stats = await db.query(` SELECT COUNT(*) as total_users, COUNT(*) FILTER (WHERE last_login > NOW() - INTERVAL '7 days') as active_users, AVG(order_count) as avg_orders_per_user FROM users`);
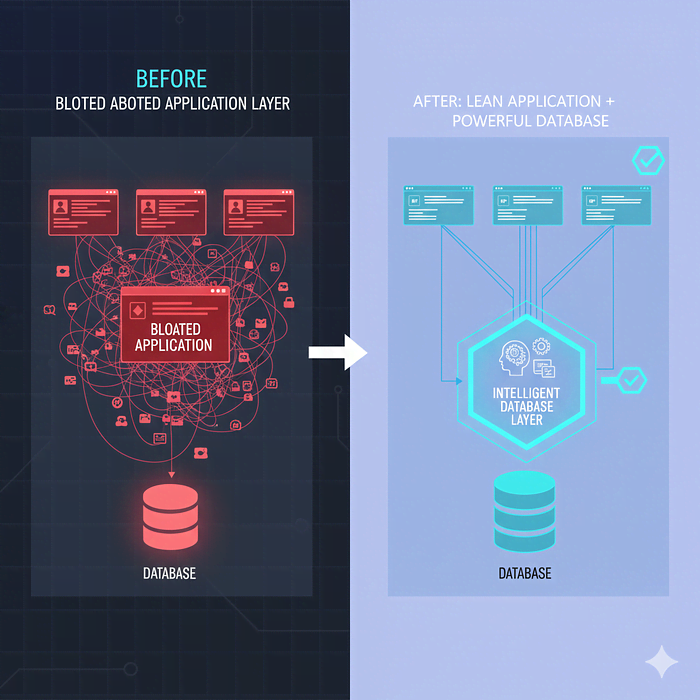
现代数据库拥有令人难以置信的功能,但大多数开发者从未接触过:
SELECT date, revenue, SUM(revenue) OVER (ORDER BY date) as running_total, RANK() OVER (ORDER BY revenue DESC) as revenue_rankFROM daily_revenue;
试试在应用程序代码中做这个,我等着你!
将复杂查询拆分成可读的部分:
WITH high_value_customers AS ( SELECT customer_id, SUM(amount) as total FROM orders GROUP BY customer_id HAVING SUM(amount) > 10000),recent_orders AS ( SELECT * FROM orders WHERE created_at > NOW() - INTERVAL '30 days')SELECT c.name, hvc.total as lifetime_value, COUNT(ro.id) as recent_ordersFROM customers cJOIN high_value_customers hvc ON c.id = hvc.customer_idLEFT JOIN recent_orders ro ON c.id = ro.customer_idGROUP BY c.id, c.name, hvc.total;
这比用多个循环编写的等效应用程序代码更具可读性。
PostgreSQL可以直接处理JSON:
SELECT id, metadata->>'name' as name, metadata->'preferences'->>'theme' as themeFROM usersWHERE metadata @> '{"status": "active"}';
不需要在你的应用中反序列化JSON。数据库处理它。
让数据库维护衍生值:
CREATE TABLE products ( id SERIAL PRIMARY KEY, price DECIMAL(10,2), tax_rate DECIMAL(3,2), price_with_tax DECIMAL(10,2) GENERATED ALWAYS AS (price * (1 + tax_rate)) STORED);
永远不要再在代码中计算 price_with_tax 了。它总是正确的。
使用数据库来强制执行业务规则:
CREATE TABLE orders ( id SERIAL PRIMARY KEY, quantity INTEGER CHECK (quantity > 0), status VARCHAR(20) CHECK (status IN ('pending', 'processing', 'completed', 'cancelled')), completed_at TIMESTAMP, CONSTRAINT completed_orders_must_have_date CHECK (status != 'completed' OR completed_at IS NOT NULL));
你的应用程序代码无法意外违反这些规则。
开始这样想:
“数据库是一个强大的处理器。我的应用程序协调它。”
你的应用程序应该:
处理HTTP请求
验证用户身份
验证输入
用设计良好的查询调用数据库
返回结果
处理错误
你的数据库应该:
存储数据
处理数据
聚合数据
过滤数据
连接数据
强制约束
返回正好需要的内容
把所有逻辑都放进数据库
永远不在你的应用程序中处理数据
所有东西都用存储过程
完全放弃ORM
我是说:
用数据库做它擅长的事
不要传输和处理你不需要的数据
当有意义时编写SQL
让数据库执行基于集合的操作
需要平衡。有些逻辑属于应用程序代码:
复杂的业务工作流
与外部服务的集成
任何需要分支到多个系统的操作
用户特定的格式化和呈现
但是数据聚合、过滤和转换呢?那是数据库的领域。
在我们转变了思维模式并重写了关键查询之后,我们的应用程序发生了转变:
仪表板加载时间: 7.8秒 → 47毫秒(快166倍)
API响应时间: p95从3.2秒降至180毫秒
数据库CPU使用率: 下降了40%(数据传输减少)
应用程序内存使用: 下降了60%(不再持有巨大数据集)
Redis成本: 下降了70%(所需缓存减少)
开发者幸福感: 大幅提升(更快的反馈循环)
我们仍然在使用Node.js和React,我们仍然在使用ORM进行基本操作。
但是我们不再把数据库当作愚蠢的存储桶,而是开始把它当作强大的计算引擎来使用,这一点带来了天壤之别的体验。
来源丨网址:https://bhavyansh001.medium.com/the-single-biggest-mistake-teams-make-with-databases-e6ed980c0655
该文章在 2025/12/31 10:38:32 编辑过






 400 186 1886
400 186 1886


