30天学会Python编程:13. Python迭代器与生成器编程指南
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
|
| 核心方法 | __iter__() | __iter__()__next__() |
| 状态 | ||
| 消耗性 | ||
| 常见类型 |
编程技巧:
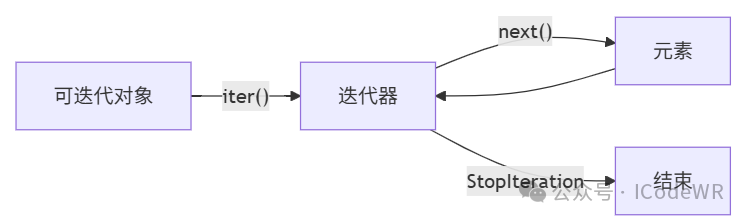
iter()函数获取对象的迭代器next()函数手动获取下一个元素StopIteration异常处理迭代结束class CountDown:
"""倒计时迭代器"""
def__init__(self, start):
self.current = start
def__iter__(self):
returnself
def__next__(self):
ifself.current <= 0:
raise StopIteration
num = self.current
self.current -= 1
return num
# 使用示例
for num in CountDown(5):
print(num, end=" ") # 输出: 5 4 3 2 1
注意事项:
__iter__方法并返回自身__next__ 方法在无更多元素时应抛出StopIteration异常生成器是创建迭代器的简洁工具,使用yield关键字暂停函数执行并返回值。
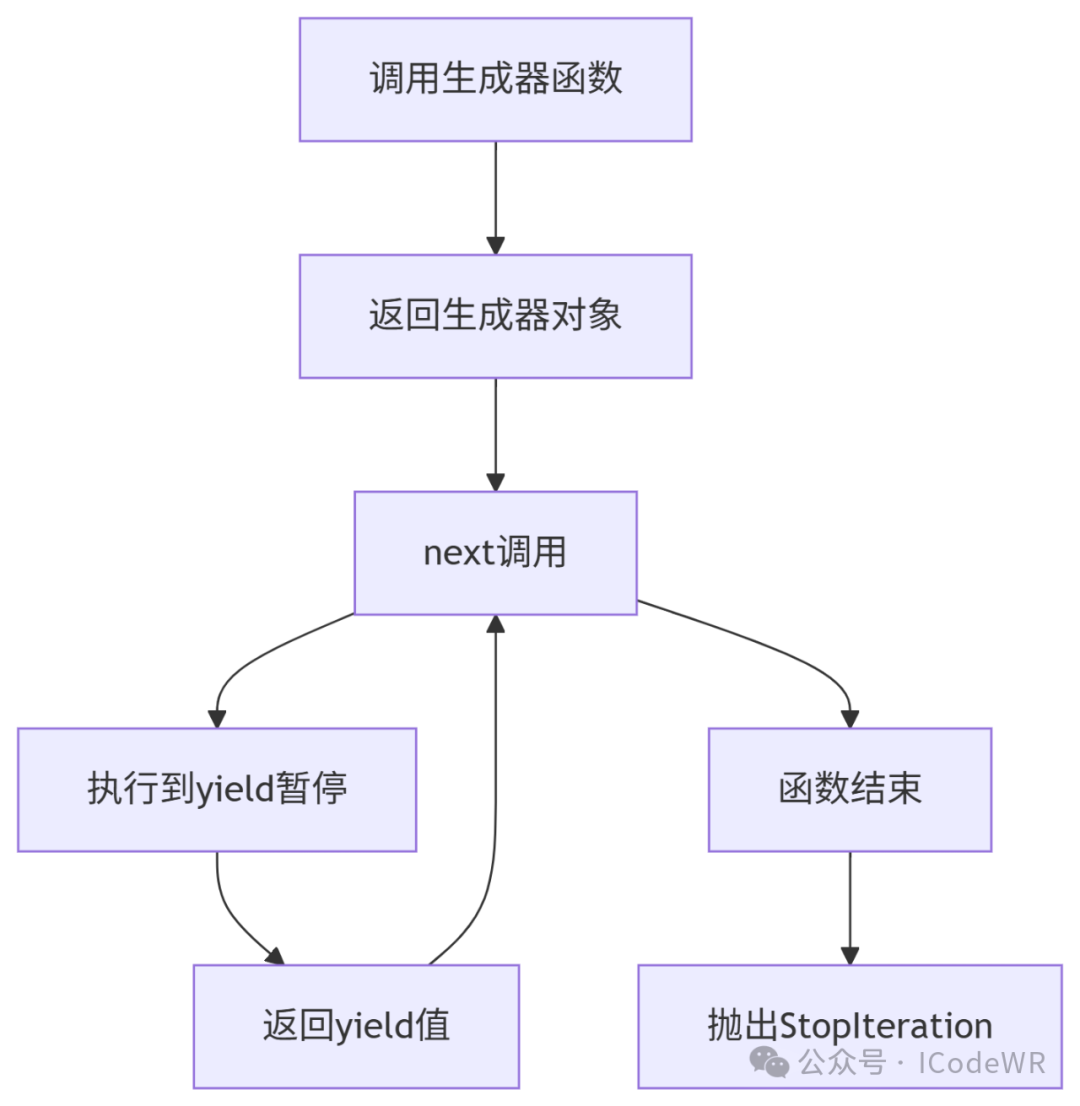
关键特性:
def fibonacci_gen(max_count):
"""斐波那契数列生成器"""
a, b = 0, 1
count = 0
while count < max_count:
yield a
a, b = b, a + b
count += 1
# 使用示例
fib = fibonacci_gen(10)
print(next(fib)) # 0
print(next(fib)) # 1
print(next(fib)) # 1
# ... 可继续获取后续值
高级技巧:
send()方法向生成器发送值throw()方法向生成器抛出异常close()方法提前终止生成器生成器表达式语法类似列表推导式,但使用圆括号而非方括号:
# 列表推导式(立即计算)
squares_list = [x**2 for x in range(10)]
# 生成器表达式(惰性计算)
squares_gen = (x**2 for x in range(10))
生成器表达式可链式组合,形成高效的数据处理管道:
numbers = range(100)
# 创建处理管道
pipeline = (
n * 2 # 步骤1: 加倍
for n in numbers
if n % 3 == 0 # 步骤2: 过滤3的倍数
if n % 5 == 0 # 步骤3: 过滤5的倍数
)
print(sum(pipeline)) # 计算100以内3和5的公倍数加倍后的和
性能优势:
生成器可通过yield接收值,实现简单的协程:
def data_processor():
"""数据处理协程"""
print("协程启动")
result = None
whileTrue:
data = yield result # 接收数据并返回结果
if data isNone:
break
print(f"处理数据: {data}")
result = data * 2 # 处理逻辑
# 使用协程
processor = data_processor()
next(processor) # 启动协程(首次必须调用)
print(processor.send(10)) # 输出: 处理数据: 10 返回: 20
print(processor.send(15)) # 输出: 处理数据: 15 返回: 30
processor.close() # 关闭协程
yield from用于简化嵌套生成器的代码:
def chain_generators(*iterables):
"""链式生成多个可迭代对象"""
for it in iterables:
yield from it # 等价于 for item in it: yield item
combined = chain_generators([1, 2], (3, 4), "ab")
print(list(combined)) # [1, 2, 3, 4, 'a', 'b']
关键用途:
def read_large_file(file_path, chunk_size=1024*1024):
"""逐块读取大文件"""
withopen(file_path, 'r', encoding='utf-8') as f:
whileTrue:
chunk = f.read(chunk_size) # 每次读取指定大小
ifnot chunk:
break
yield chunk
# 使用生成器处理100GB文件
word_count = {}
for chunk in read_large_file('huge_file.txt'):
# 处理每个块而不加载整个文件
process_chunk(chunk, word_count)
import random
import time
defsensor_data(sensor_id):
"""模拟传感器数据流"""
whileTrue:
yield {
'timestamp': time.time(),
'value': random.uniform(0, 100),
'sensor_id': sensor_id
}
time.sleep(0.5) # 模拟数据间隔
# 创建数据处理管道
defdata_pipeline(sensors):
for sensor in sensors:
yieldfrom (
transform_data(data)
for data in sensor
if validate_data(data)
)
# 使用示例
sensors = [sensor_data(f"sensor_{i}") for i inrange(3)]
for processed in data_pipeline(sensors):
print(processed)
if processed['value'] > 95:
trigger_alert(processed)
内存敏感操作:使用生成器替代列表
# 不良实践:加载整个文件到内存
with open('large.txt') as f:
lines = f.readlines() # 可能耗尽内存
# 最佳实践:使用生成器逐行处理
with open('large.txt') as f:
for line in f: # 文件对象本身就是生成器
process(line)
高效过滤与转换:
# 使用生成器表达式
large_data = (x for x in get_huge_dataset() if x > 0)
transformed = (transform(y) for y in large_data)
# 替代列表推导式
result = [process(z) for z in transformed] # 最后一步才物化
| 迭代器 | __iter__和__next__ | |
| 生成器函数 | yield暂停/恢复 | |
| 生成器表达式 | (x for x in ...) | |
| 协程 | send()yield双向通信 |
实践建议:
yield from简化嵌套生成器next()启动常见问题:
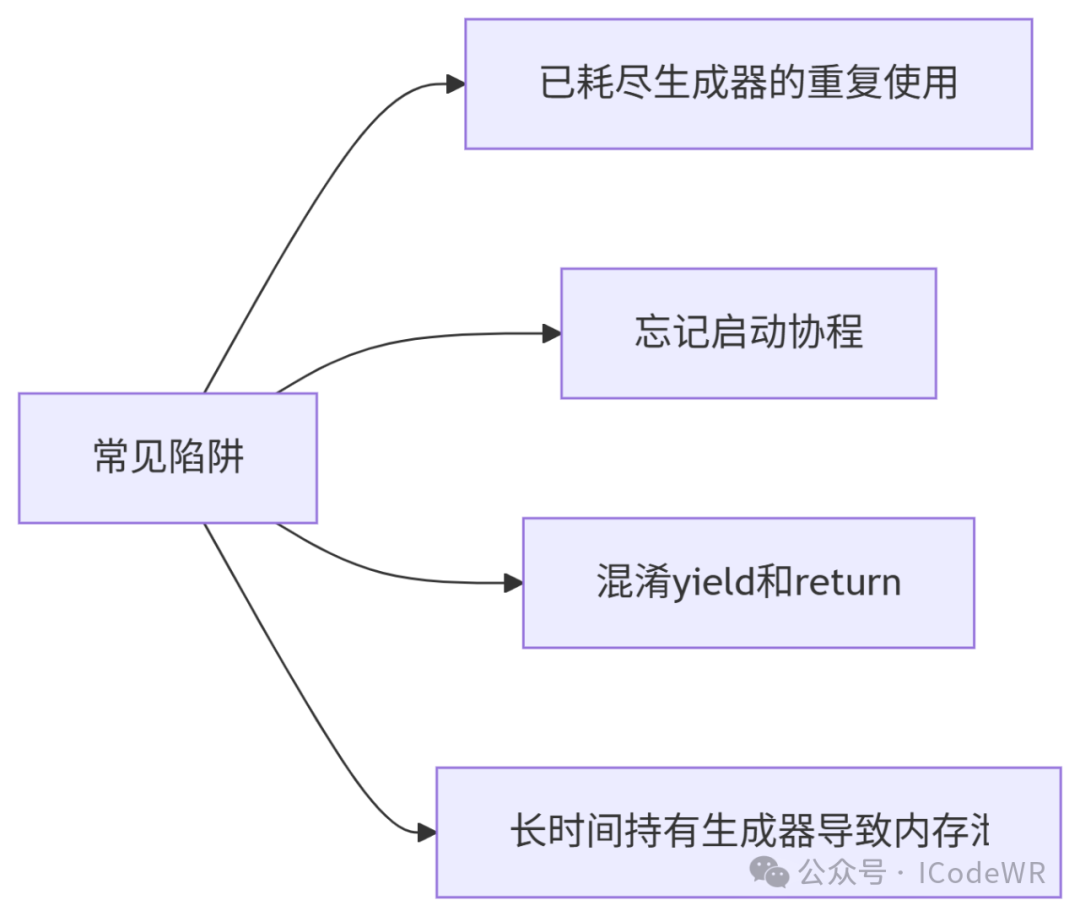
解决方案:
next(coro)yield暂停而非返回异步编程:深入async/await语法
async def async_fetch(url):
response = await aiohttp.request('GET', url)
return await response.text()
上下文管理器:使用生成器实现
from contextlib import contextmanager
@contextmanager
def managed_resource():
resource = acquire_resource()
try:
yield resource
finally:
release_resource(resource)
状态机实现:
def traffic_light():
states = ['RED', 'YELLOW', 'GREEN']
index = 0
while True:
yield states[index]
index = (index + 1) % len(states)
生成器式协程调度:
def scheduler(coros):
while coros:
try:
coro = coros.pop(0)
next(coro) # 执行一步
coros.append(coro) # 放回队列
except StopIteration:
pass # 协程完成
迭代器和生成器是Python编程中的核心概念,它们提供了:
掌握这些概念将显著提升我们处理复杂任务和大规模数据的能力,并为理解Python的异步编程模型打下坚实基础。
阅读原文:原文链接






 400 186 1886
400 186 1886